
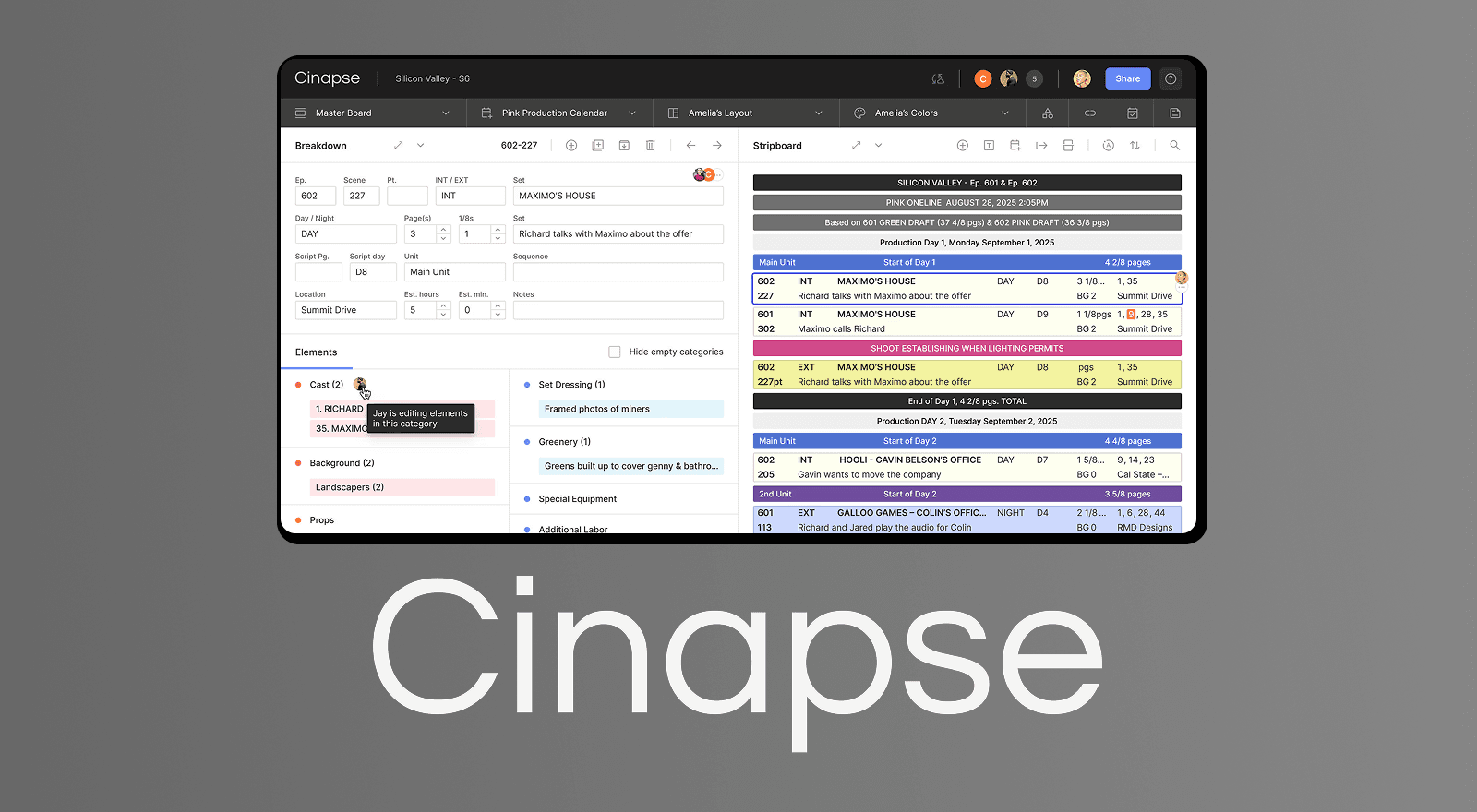
Cinapse is scheduling software for film and TV production. Our users are production teams with two important needs: (1) offline availability and (2) easy collaboration.
I’ve built offline-first, collaborative apps before, but Cinapse’s scheduling app was the first one I built from scratch using CRDTs. I learnt a lot through this process: ultimately migrating away from CRDTs and preferring PowerSync’s server-authoritative architecture. CRDTs are an impressive and exciting technology, but they turned out to be a bad fit for our use case. Hopefully sharing our experience helps others who are considering building apps with real-time sync.
Our introduction to CRDTs
Before we built our scheduling app, Cinapse had a more limited app used for managing cast and crew on set. We targeted mobile for this app and built it with React Native. We came across CRDTs when we initially faced the challenge of syncing changes made by one user to other users in real-time.
This was around 2020, and CRDTs looked like the perfect fit for this use case. Automerge stood out as a CRDT sync engine since it is JSON-based, which meant that we were able to incorporate it into our existing data structures with minimal work. The Automerge project is led by some big names in the CRDT space which only reinforced that this was the solution for us. We also considered Yjs but ultimately decided on Automerge because of its JSON-based nature: to put it simply, manipulating a JSON object using traditional JSON methods is a far less steep learning curve than learning Yjs-specific functions, which for our team was paramount due to the turnaround time allowed for this integration. As an example: when using Yjs, you are required to instantiate an array using the Yjs.Array constructor, whereas Automerge would simply be a JavaScript array (or []).
We implemented Automerge and it worked very well for the cast & crew management use case. So when we pivoted to tackle the bigger industry challenge of scheduling, we considered designing that app around Automerge and CRDTs from day one.
Building a collaborative app from scratch using Automerge
Table stakes and differentiators
While offline availability was expected, we knew from the start that well-designed collaboration would be critical to differentiating our scheduling app from legacy competitors. At the time, the consensus was that CRDT systems were the way to build offline-first apps.
Our team was already familiar with the Automerge approach, so it felt natural to start there. Since collaboration and conflict resolution (sometimes at a fairly fine-grained level, like sortable lists) were core requirements, and Automerge was purpose-built for offline-first systems, it seemed like the perfect starting point to ensure the app could function as we envisioned.
We decided to choose our tech stack around Automerge and CRDTs rather than trying to build that in after the fact. Since scheduling is mostly done on large screen devices like laptops and iPads, a web app built with React was a good fit. Automerge is not difficult to set up, especially with the automerge-repo packages, and I still view it as an easy recommendation if you don’t have a project that will require large CRDT files with complex data structures.
Automerge in a nutshell
Automerge is a CRDT library. V1 of Automerge was originally a JavaScript library, and was slow. This prompted the Automerge team to migrate to a Rust implementation which compiles to WebAssembly for use in JavaScript environments. This shipped with Automerge V2.
Automerge V3 is a recent release, which optimizes the internals of the Rust library, making huge gains in the memory footprint of Automerge, e.g. bringing memory usage down by more than 10x. We never had the opportunity to evaluate Automerge V3 because we needed a solution before it was ready.
automerge-repo is a JavaScript wrapper for the Automerge CRDT library. It provides all the plumbing for working with multiple documents as well as pluggable networking and storage. Automerge recommends using automerge-repo as their batteries-included implementation.
Constraints discovered
Because Automerge compiles to WebAssembly for use in JavaScript environments, and WebAssembly has a 32-bit memory model, there is a hard memory limit of 4GB.
For our scheduling use case, users typically work on the same file for an extended period of time: producing a film or TV series can take months or even years. This creates a really large history, which in Automerge V2 was contained in the CRDT itself. These large CRDT files require a lot of memory — frequently at the upper limit of the 4GB available.
Since automerge-repo is the recommended way to implement Automerge, our Automerge sync servers needed to run in a JavaScript environment (Node.js for us) and came with the same memory constraints mentioned above. This was the choke point of the system for us: to support a large number of files or even very large files, we needed to spin up additional servers purely because of this limitation.
As file sizes of our customers increased, we were forced to throw money at the problem just as a band-aid. We were burning around $1,000/month on Automerge sync servers for some customers with really large files. We needed to find a solution.
Reasoning about alternatives
A core realization was that the per-character tracking done by CRDTs was not necessary for our use case , since the data structure that needed to be synced was not a giant chunk of text but rather individual properties or fields. At worst, we might need CRDTs within certain fields, but this was also unlikely since even though our system includes data used by multiple users, each user typically has a distinct role and mostly edits only their subset of data which is rolled up into the schedule view.
In general, for a scheduling use case like ours, the outline of the project is already understood by the time the scheduling happens. It would be more accurate to describe putting that outline into a schedule as an act of “translation” rather than the type of collaboration (e.g. text editing) that CRDTs are a good fit for.
With this insight, we became open to considering sync engine alternatives that were not based on CRDTs.
Alternatives considered
Timeline was important for us : we couldn’t continue burning money on infrastructure. For this reason we couldn’t wait for Automerge’s V3 release. Even though it seemed like a good option at the time, in hindsight it’s clear that V3 would still not have solved the problem of ever-growing CRDT file sizes. We looked into Electric-SQL but they were going through a rewrite.
So in addition to the hope that Automerge might release V3 soon enough to stop our bleeding, the alternatives we seriously considered were PowerSync, Yjs, and OrbitDB + IPFS.
For each of these alternatives, we tried to get an understanding of general pros and cons as well as migration complexity. Here are my notes from this evaluation:
PowerSync
-
PowerSync provides a database replication-based solution that supports offline-first and real-time collaboration requirements without CRDT complexity.
-
Pros:
- Efficient Large File Handling: Instead of relying on a single JSON structure, it leverages a database-backed approach, which can better handle large datasets.
- Offline-First: PowerSync’s model is offline-first by design, supporting local data storage and syncing with the server once back online.
- Real-Time Collaboration: Enables real-time collaboration similar to CRDTs, but without the same overhead.
- Security: Built with encryption capabilities for data at rest and in transit, aligning with your security requirements.
-
Cons:
- Migration Complexity: Migrating from automerge-repo could be complex, as it would involve restructuring your data from a single JSON model to a database-oriented model.
- Custom Conflict Resolution: PowerSync does not inherently provide a CRDT-like conflict resolution model, so you may need to handle conflicts, especially in a last-change-wins scenario.
-
Migration Complexity:
- Data Model Transformation: Your current single JSON structure would need to be broken down and reorganized into a relational or NoSQL database format.
- Sync Strategy: While PowerSync handles sync, you may need custom code to adapt Automerge’s sync semantics (e.g., merging timestamps) to PowerSync’s replication methods.
- Offline State Management: automerge-repo’s built-in sync model would be replaced by PowerSync’s replication approach. This means that reading and displaying local data would require some additional overhaul, primarily due to the fact that the data is now in a database as opposed to an in-memory object.
Yjs
-
Yjs is a high-performance CRDT library that supports real-time collaboration with a memory-efficient, binary-based approach. It is designed for scalability and can handle large documents better than Automerge due to its garbage collection mechanism and binary encoding.
-
Pros:
- Efficient Memory Usage: The binary encoding and garbage collection mechanisms help Yjs scale better than JSON-based CRDTs, making it suitable for complex and frequently updated data.
- Real-Time and Flexible Sync: Yjs supports multiple network providers (WebSocket, WebRTC) and sync strategies, making it adaptable to various real-time needs.
- Security: Yjs doesn’t inherently handle encryption, so encryption would need to be layered on top.
- Conflict Resolution: CRDT-based, which inherently handles conflicts and merges changes without needing explicit logic.
-
Cons:
- Migration Complexity: Migrating from automerge-repo to Yjs may be more complex than transitioning to PowerSync due to different data structures and CRDT models.
- Offline-First Limitations: Yjs is designed with real-time in mind, so implementing offline-first functionality requires additional layers or custom logic.
-
Migration Complexity:
- Data Structure Transformation: You’ll need to translate your JSON structure into Yjs’s more modular approach (e.g., Y.Text, Y.Map), which might require significant re-engineering.
- Sync Layer: Adapting automerge-repo’s sync engine to Yjs’s multi-provider sync model could add complexity.
- State and Conflict Resolution: Though Yjs handles conflicts well, implementing offline support would require additional code to manage state and conflict resolution after going offline.
Automerge
-
Automerge is a JSON-based CRDT library that excels in offline-first applications by automatically syncing changes and resolving conflicts with a “last-write-wins” model. Its WebAssembly-based memory limit, however, makes it challenging to scale for large files.
-
Pros:
- Offline-First: Automerge is offline-first by design, making it ideal for applications that need local-first data handling with sync capabilities.
- Automatic Conflict Resolution: Automerge’s CRDT model resolves conflicts automatically, which simplifies collaborative application logic.
- Built-in Sync: automerge-repo’s built-in sync engine provides an end-to-end sync model out of the box.
-
Cons:
- Memory Consumption: Automerge’s JSON-based approach is memory-intensive and struggles with large files, constrained by WebAssembly’s 4GB memory limit.
- Scaling Issues: For large files or datasets, Automerge’s performance deteriorates, impacting business performance, as we’ve experienced.
-
Migration Complexity:
- No migration needed
OrbitDB + IPFS
-
OrbitDB, a peer-to-peer database, runs on top of IPFS (InterPlanetary File System) and allows offline and distributed data storage with eventual consistency. It’s designed for offline-first, decentralized applications and handles large data by distributing it across nodes.
-
Pros:
- Offline-First and Decentralized: Designed to work offline and sync over a decentralized network, which is ideal for distributed and offline-first use cases.
- Efficient with Large Files: Leveraging IPFS’s DHT allows OrbitDB to store large files in a decentralized, memory-efficient manner.
- Security: OrbitDB provides built-in data encryption and can operate securely over a distributed network.
-
Cons:
- Peer-to-peer database: peer-to-peer data synchronization is not ideal given our authoritative approach to data integrity.
- More Complex Setup: IPFS and OrbitDB require more setup and a distributed infrastructure, which may be more complex to integrate than PowerSync.
-
Migration Complexity:
- Data Structure and Distribution: OrbitDB uses a document-store model, so migrating from a single JSON file may involve restructuring and distributing data.
- Sync Complexity: OrbitDB’s sync model, which relies on IPFS, differs significantly from automerge-repo’s built-in sync engine. This would require re-architecting your sync layer and handling the switch from real-time to eventual consistency.
- Security Layer: While OrbitDB provides encryption, ensuring consistency and data security during migration may need a custom setup.
A big reason for choosing PowerSync was that it theoretically allowed for a rework to the way that data is loaded in the UI that didn’t require a complete rewrite. In contrast, If we moved to Yjs, for example, the UI would need to be reworked to use Yjs structures (as mentioned above). The way that this is avoided with PowerSync is that data is loaded from the database into the exact same shape as the Automerge objects that had been used previously.
Implementing PowerSync
Migrating to PowerSync did not come without challenges. For starters, the mental model was completely different and required converting our JSON structure into a database schema that allowed us to minimize rewriting code. Figuring out how to get existing code to work with both Automerge and PowerSync was a hard but important task, since it allowed us to migrate to PowerSync incrementally.
Here’s a snippet showing how we would load an element using our paradigm for loading “elements” via Automerge and PowerSync in a consolidated manner:
export function useElement(id: string): { element: Element | undefined } {
const sync = useQueryParam('sync')
const powersync = useMemo(() => sync === 'v2', [sync])
//both hooks run due to React restriction
const automergeData = useElementAutomerge(id)
const powersyncData = useElementPowersync(id)
return useMemo(
() => (powersync ? powersyncData : automergeData),
[automergeData, powersync, powersyncData],
)
}
function useElementAutomerge(id: string): { element: Element | undefined } {
const [document] = useDocument() //automerge-repo/react provided hook
const { element } = useMemo(() => {
const allElements = document?.elements ?? {}
const element = allElements[id]
return { element }
}, [document?.elements, id])
return { element }
}
function useElementPowersync(id: string): { element: Element | undefined } {
const fileId = useQueryParam('id')
const db = useKysely() //custom kysely wrapper around powersync db
const query = useMemo(
() =>
db
.selectFrom('element')
.selectAll()
.where('id', '=', id)
.where('file_id', '=', fileId)
.limit(1),
[db],
)
const { data: rows, ..._rest } = useQuery(query)
const element = useMemo(() => {
if (rows?.length !== 1) return undefined
const row = rows[0]
if (!row) return undefined
const element: Element = {
id: row.id,
isHold: Boolean(row.is_hold),
... //rest of assignments
}
return element
}, [rows])
return { element }
}In addition, denormalizing data and making sure we were using the correct references was tedious at times, and because PowerSync doesn’t support relations and constraints out of the box, queries that work client-side sometimes fail when it needs to be synced.
Post migration experience
Since migrating to PowerSync’s server-authoritative model, the impact has been significant:
-
Support Load
- We saw an 89% reduction in support requests , largely because the infrastructure now handles large datasets far more reliably.
-
Costs
- Hosting expenses dropped by 66% , and even with the user base doubling, costs have only climbed back to about 50% of what they were originally.
-
Throughput
- Raw throughput was technically faster with Automerge, since changes were consolidated per client. PowerSync’s approach processes changes on the server instead, which trades some throughput for consistency and reliability at scale.
-
Data Integrity
- Data reliability improved substantially. Automerge struggled with memory constraints and in-memory document limits, whereas PowerSync saves and reads directly from the database, avoiding those pitfalls.
PowerSync fundamentally solved our scaling and reliability challenges. The server-authoritative architecture delivers deterministic synchronization that performs consistently whether users are working on small Indie projects or enterprise-scale productions. Offline functionality now works reliably: users can disconnect for hours or days, make extensive changes, and trust that everything will reconcile correctly when they reconnect.
More importantly, PowerSync eliminated an entire class of infrastructure problems that previously consumed engineering resources and generated support tickets. Where we once spent significant time firefighting data integrity issues and memory constraints, we now have a system that scales predictably and requires minimal intervention. The combination of reduced operational burden, lower costs, and rock-solid reliability has allowed us to focus on building features instead of maintaining infrastructure.