

Since this post was published, PowerSync has released Sync Streams, which support INNER JOINs with simple equality conditions. The use case described in this post can now be handled using Sync Streams. However, for more complex joins (e.g. many-to-many), pg_ivm remains a valid approach, and this post may still serve as a useful reference.
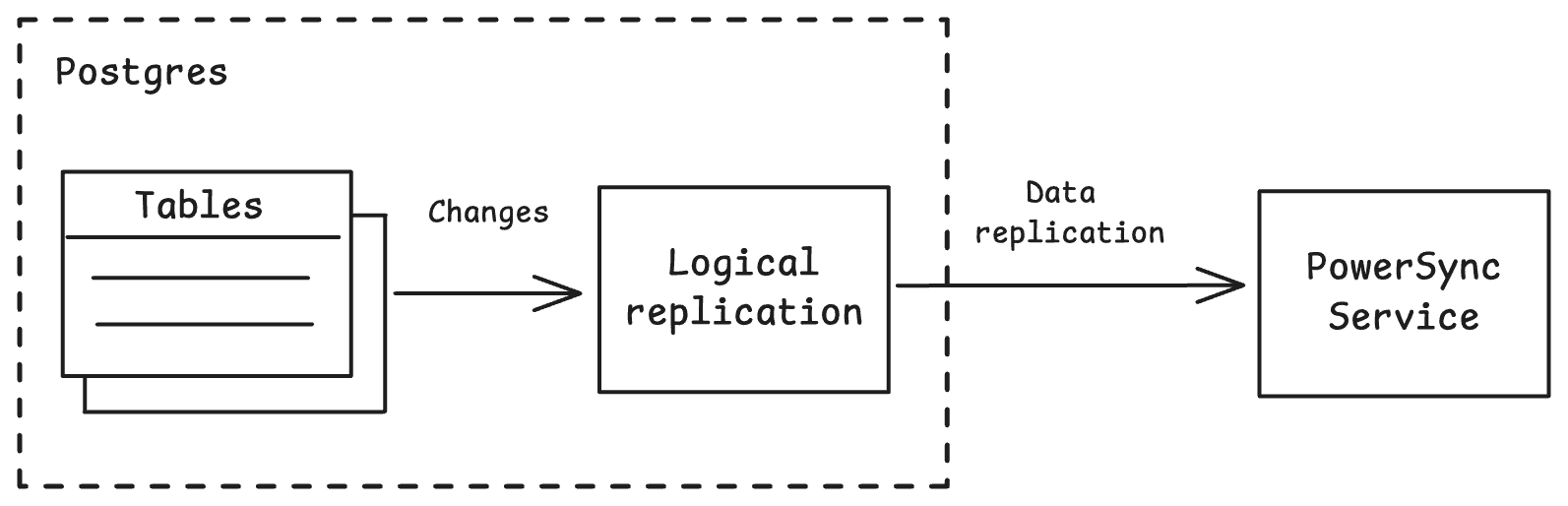
PowerSync keeps in-app SQLite databases in sync by replicating data changes from backend source databases. When using Postgres as the source database, this happens via Postgres logical replication, which is derived from the Write-Ahead Log (WAL). Using this approach, PowerSync gets a stream of changes that occur in Postgres, allowing for high-performance, scalable and efficient syncing.
The specific data that should be replicated is defined using Sync Streams (or legacy Sync Rules) on the PowerSync Service, which make use of SQL-like query statements.
3+ table JOINs not yet supported
Since this post was originally published, PowerSync has introduced** Sync Streams** _, which support 3+ table INNER JOINs. For many common use cases, this means the approach described below is no longer required.
_
However, this post remains a useful reference. The example below explains how normalized relational data can be synced by restructuring queries and relationships. While Sync Streams now handle simple JOINs directly, the same principles described here can still be applied when working with more complex joins (for example, many-to-many relationships).
Consider the following example: Let’s say we have Orders that belong to Customers, and we want to sync certain customers with their associated orders:
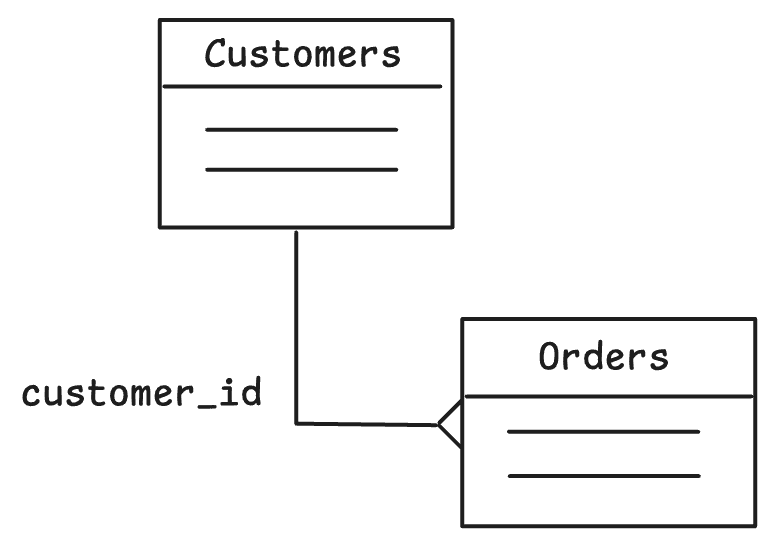
Since we only need a 2-table join in this scenario, we can make use of the Orders table’s customer_id foreign key in the Sync Rules:
parameters: SELECT request.jwt() ->> 'customer_id' as customer_id
data:
- SELECT * FROM customers WHERE id = bucket.customer_id
- SELECT * FROM orders WHERE customer_id = bucket.customer_idThe problem comes in when we have a tertiary relationship. Let's say we expand the above example to include a Line Items table linked to an order:
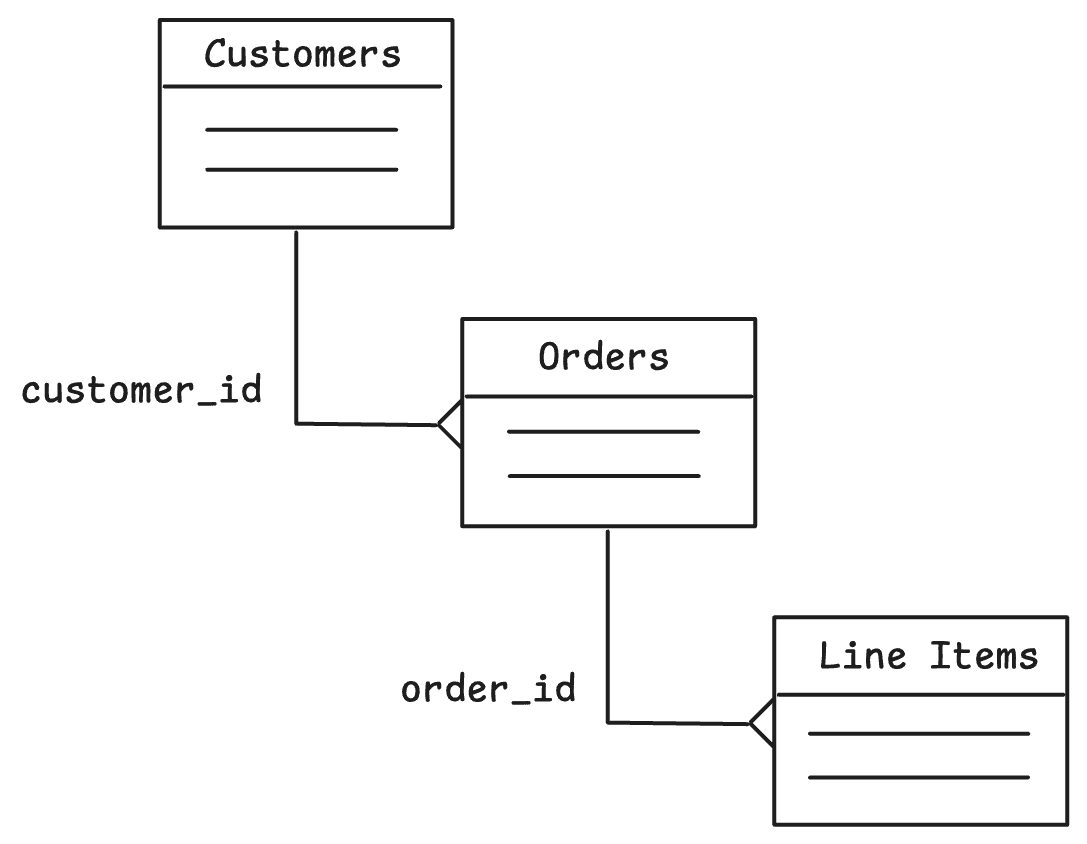
How do we create the Sync Rules to represent this?
parameters: SELECT request.jwt() ->> 'customer_id' as customer_id
data:
- SELECT * FROM customers WHERE id = bucket.customer_id
- SELECT * FROM orders WHERE customer_id = bucket.customer_id
- SELECT * FROM line_items WHERE line_items.order_id = ?PowerSync doesn’t have a built-in solution yet to sync based on the relationships across these 3 tables without changing your schema.
Denormalization workaround
The generally recommended workaround is to denormalize the relationships in your schema: By adding a customer_id column to the Line Items table, we can use the following to sync all the Orders and Line Items that belong to the relevant Customers:
parameters: SELECT request.jwt() ->> 'customer_id' as customer_id
data:
- SELECT * FROM customers WHERE id = bucket.customer_id
- SELECT * FROM orders WHERE customer_id = bucket.customer_id
- SELECT * FROM line_items WHERE customer_id = bucket.customer_id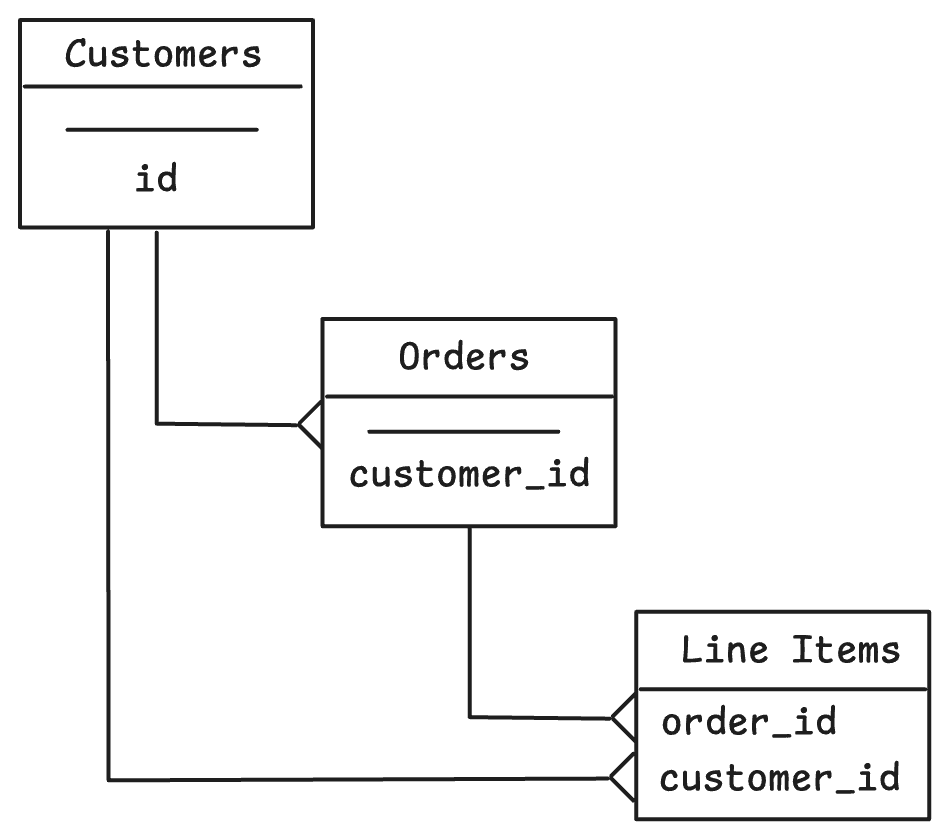
Note that while arbitrary JOINs are not yet supported in Sync Rules, JOINs are supported in the client-side SQLite database that the data is synced to. So in the client-side application, we can write queries with JOINs as needed.
Unfortunately, denormalizing relationships has drawbacks such as:
- The effort to refactor the database schema
- Redundant data (duplication)
- Increased vulnerability to data inconsistencies
Fortunately, there is another alternative solution: The pg_ivm extension for Postgres.
What is IVM and what does pg_ivm do?
A materialized view is a stored, precomputed result of a query that behaves like a table and can be refreshed to stay up to date. Incremental View Maintenance (IVM) is a technique used to efficiently update materialized views: instead of refreshing the entire view when the underlying data changes (by re-running the whole query), the view is incrementally updated. The pg_ivm extension for Postgres implements this technique, allowing developers to create materialized views that are efficiently automatically updated as the base tables are modified.
Postgres includes built-in materialized views, but they don’t provide IVM: They need to be refreshed manually (REFRESH MATERIALIZED VIEW my_view) which can be an expensive operation, and the changes to the view are not published to the logical replication stream.
By contrast, the “materialized views” created by pg_ivm are just regular Postgres tables that are kept up to date using an IVM algorithm — and therefore changes to these tables are published in logical replication.
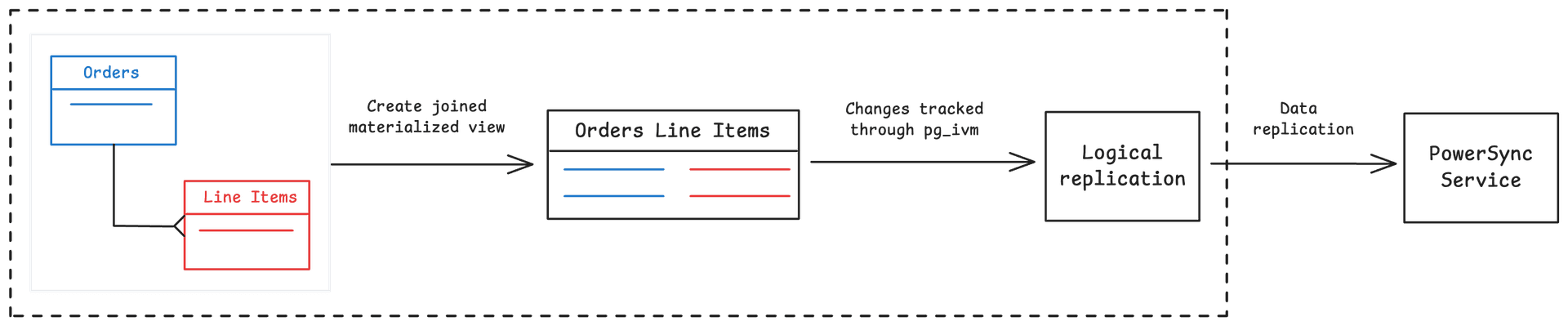
Using pg_ivm for JOINs in PowerSync
To use pg_ivm with PowerSync, create a materialized view using pg_ivm that includes JOINs, and reference it in PowerSync’s Sync Streams like any other table.
Note: There are some limitations to the types of queries that can be used with pg_ivm. For details on what type of clauses and aggregations are supported, see this section from the README.
pg_ivm demo
A working demo of the above example can be found at powersync-pg_ivm-example repository.
The schema includes customers, orders and line_items tables, and then implements an incrementally materialized view of line_items_ivm using pg_ivm: (see setup.sql)
CREATE EXTENSION pg_ivm;
SELECT
pgivm.create_immv('line_items_ivm',
'SELECT li.id,
c.id AS customer_id,
c.name AS customer_name,
o.id AS order_id,
o.reference AS order_reference,
li.product_name
FROM customers AS c
JOIN orders AS o ON c.id = o.customer_id
JOIN line_items AS li ON o.id = li.order_id');
ALTER TABLE line_items_ivm REPLICA IDENTITY FULL;Note on that last SQL statement: By default, when you create a logical replication publication for a table in Postgres, it uses the table’s primary key to allow subscribers to identify existing rows on which UPDATE and DELETE operations happened. If a table does not have a primary key, like our materialized view in the above example, Postgres will throw an error unless you enable REPLICA IDENTITY FULL, which publishes the entire row as an identifier in the logical replication stream.
Caveat: Offline updates to SQLite database
There is an important drawback to this approach to take note of: Because these materialized views are updated server-side in Postgres, changes made locally in the client-side SQLite database (while offline) won’t immediately reflect in the materialized view until the next sync cycle.
This means that the normal pattern of using PowerSync breaks a bit. For example, you might be using PowerSync’s watched queries like this:
powerSync.watchWithCallback(
`SELECT *
FROM orders
JOIN line_items ON orders.id = line_items.order_id
WHERE orders.id = 1`,
[],
{
onResult: (rows) => {
const orders = rows.rows?._array;
console.log("Watch orders result:", orders);
},
}
);
console.log("Updating a line item...");
await powerSync.execute(`UPDATE line_items SET product_name = ? WHERE order_id = 1`, ["test"]);With pg_ivm we lose this live SQLite feedback in the client. Mutations on the underlying tables (like line_items) require a full roundtrip synchronization (updateData → source Postgres database → PowerSync Service → local SQLite database) to be reflected in the materialized view table (line_items_ivm).
Supported cloud providers
The only managed cloud Postgres providers we know of that currently support extensions and therefore pg_ivm are:
- Neon — see also Google Cloud SQL’s extension list
- Google Cloud SQL (take note of the warnings)
- CrunchyBridge