
Note: This blog post applies to the original legacy version of ElectricSQL. On July 17, 2024, Electric announced a “clean rebuild” of their sync engine, which was initially called ‘electric-next’. Development of the legacy version of ElectricSQL has been stopped. We have published a new blog post comparing ‘electric-next’ to PowerSync here.
Several people have asked us how PowerSync compares to ElectricSQL. We’ve put together this overview to answer this question more thoroughly. Please feel free to chat to us on Discord if you have any questions or comments.
Similarities between ElectricSQL (Legacy) and PowerSync
On the surface, the legacy ElectricSQL and PowerSync have similar goals and enable similar outcomes for developers: Both are designed to be a plug-in sync layer for existing application stacks — offering bi-directional syncing of data between standard Postgres 1 and client-side databases (e.g. SQLite).
Both ElectricSQL and PowerSync provide:
- Instant reactivity for your apps (by allowing your app front-end to work with a local database, with live queries)
- Offline operation of apps (read and write to a local database, and then data syncs in the background automatically when connectivity is available — both systems use some kind of upload queue on the client-side)
- Real-time multi-user collaboration (by keeping data in sync between users and devices in real-time)
Both can be used in greenfields and brownfields projects. Both use JWTs for authentication. Both use Postgres logical replication / the WAL to monitor the database for changes to be streamed to clients. Both provide causal consistency guarantees.
Key differences between ElectricSQL (Legacy) and PowerSync
While there are broad similarities between ElectricSQL and PowerSync, there are important differences in architecture.
Summary: ElectricSQL vs. PowerSync architecture
Here’s a brief overview of the fundamental differences in architecture. Some of these are explored in more detail below.
| ElectricSQL architecture | PowerSync architecture |
|---|---|
| Writes are made directly to your Postgres database via the Electric sync service (bypassing your backend application), using CRDTs to merge changes deterministically. This means that custom business logic cannot be applied to writing changes to your database on the server-side. It also has other important implications for the developer as discussed below. | Writes are sent through your own application backend, allowing you to customize how they're handled: You can apply your own business logic, fine-grained authorization, validations and server-side integrations, you can resolve conflicts using the techniques/algorithms of your choosing, and you can reject changes from clients if needed. Your backend is authoritative: After processing the write on your backend, the state will correctly and consistently replicate to clients. This does mean that some additional work is required to implement writes. Writes and conflict resolution are not automatic like with ElectricSQL. |
| Makes extensive modifications to your Postgres database (schema additions, additional storage, triggers and typically subscribing to a logical replication stream from the Electric sync service). | Does not make modifications to your Postgres database. Operation history is stored in the PowerSync Service. |
| Tightly coupled to your Postgres schema and configuration. | Loosely coupled to Postgres — creating a layer of flexibility/independence between itself and Postgres. |
| Sync controls are defined partly on the server-side (access control / permissions) and partly on the client-side (Shapes, controlling what data is synced). Note: As of the time of publishing this blog post, Shapes are currentlyexperimental. | Sync controls are defined on the server-side (Sync Rules) and can make use of dynamic parameters from the client. |
| ElectricSQL has a high memory footprint on the server-side, which impacts scalability. It keeps a graph in memory per client of all rows synced to that client and acknowledged by the client. Memory overhead is proportional to the number of client connections times the average number of rows synced per connection. | PowerSync’s Sync Rules and its principle of deduplication allows the system to scale to high volumes of data and users with an efficient server-side memory footprint: It stores bucket state and operation history (indexed for efficient querying) in persistent storage and stores limited data in memory. |
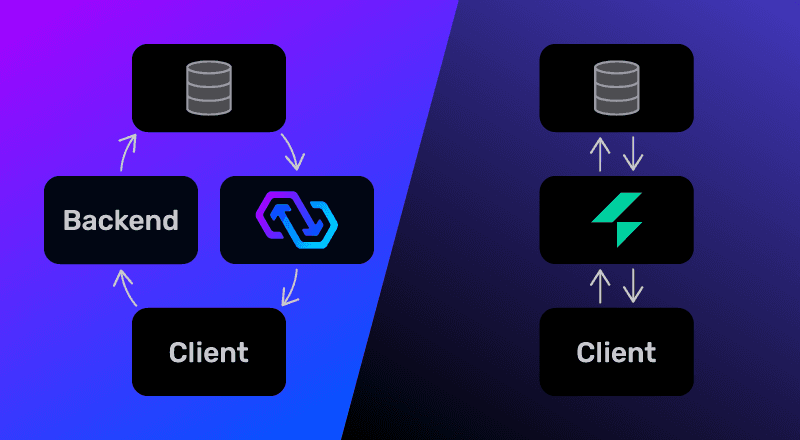
ElectricSQL’s direct-to-Postgres CRDT architecture vs. PowerSync’s authoritative backend architecture
As mentioned above, ElectricSQL writes directly to your Postgres database, using CRDTs to merge changes deterministically. At a high level, the architecture looks like this:

There are a few implications of this architecture that developers should take into consideration when weighing whether ElectricSQL is the right fit for their needs:
1. Access control & validation defined by the database
In the local-first (and offline-first) paradigm, you will typically implement much of your business logic in the client (see here), since you want the app to be fully functional regardless of network/cloud availability. However, the client-side is an untrusted environment, and therefore when writes are propagated to the server-side Postgres database, we need a way to enforce validation and authorization as a last line of defense.
With ElectricSQL there is no custom server/backend mediating the interfacing with Postgres, and ElectricSQL uses Postgres as the exclusive “control plane” for the system. This means that the Postgres database configuration is used exclusively by ElectricSQL for defining access control / validation — in other words, the database defines the line of defense for malicious client actors.
For example, user input validation has to be done using Postgres check constraints. Access control and permissions need to be defined using ElectricSQL’s DDLX which is executed in PostgreSQL as part of migrations. That being said, check constraints and DDLX access controls are not yet available in ElectricSQL at the time of publishing this blog post.
2. Server-side workflows using event sourcing
As a result of the ElectricSQL architecture, server-side workflows cannot be triggered by your backend application. Therefore, ElectricSQL recommends triggering server-side workflows using event sourcing based off of database change events. This means adding an additional system/component to your stack for database event sourcing, and integrating your backend framework with that system.
3. No custom conflict resolution
ElectricSQL applies predefined behavior to merging changes and resolving conflicts using CRDTs. For example, ElectricSQL uses the Rich-CRDT feature of ‘Compensations’ to guarantee referential integrity: If user A deletes an object while user B concurrently creates a reference to that object, the Compensation will re-create the object deleted by user A in order to preserve referential integrity.
In cases like this, the behavior of the CRDT might not be aligned with what the developer would prefer for a particular system or a particular business requirement. ElectricSQL does plan on eventually allowing the developer to select between different CRDTs / conflict-resolution policies, but this will still result in limited flexibility.
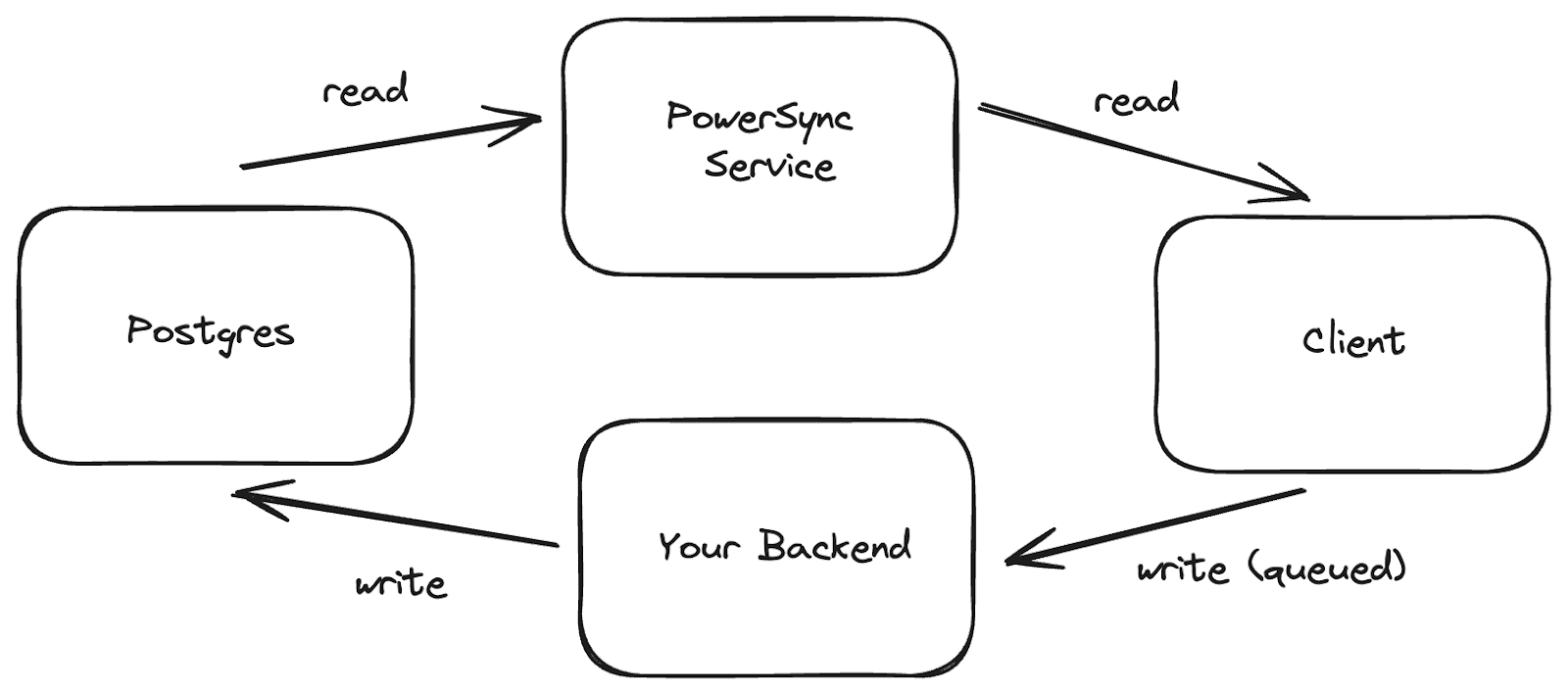
PowerSync’s authoritative backend architecture
With PowerSync, writes are sent through your own application backend 2, allowing you to customize how they’re handled: You can apply your own business logic, fine-grained authorization, validations and server-side integrations, you can resolve conflicts using the techniques/algorithms of your choosing, you can trigger server-side workflows, and you can reject changes from clients if needed. At a high level, the architecture looks like this:
Leveraging CRDTs’ strengths
At PowerSync, we believe CRDTs have great strengths: For example, they are an excellent solution for collaborative document/text editing. Although ElectricSQL’s internal merge logic uses CRDTs, ElectricSQL does not provide a built-in solution for document/text collaboration using CRDTs. It would be a similar effort to implement document/text collaboration with either PowerSync or ElectricSQL. For example, you could use Yjs and store its CRDT data structure in Postgres using blob columns, with each row in the Postgres table representing a user edit/update (or each row representing a whole document). We’ve provided an example implementation here.
Modification of your Postgres database: ElectricSQL vs. PowerSync
Another factor that developers should take into consideration when weighing whether ElectricSQL or PowerSync is the right fit for them, is the degree to which they require any changes to the Postgres database.
It should be noted that ElectricSQL makes various changes to your Postgres database:
- Adds additional “shadow tables” to your schema, which store CRDT data which are used to merge changes. This increases the data storage used by your database. At the very least it will double the size of the data accessed by ElectricSQL, and as the change history grows, it will gradually increase from there.
- Adds triggers, for example to perform merge logic.
- Typically subscribes to a logical replication stream from the ElectricSQL sync service — this is typically how changes are written into your database. ElectricSQL subsequently also added a ‘direct writes’ mode as an alternative to the logical replication subscription.
It is also worth noting that Electric requires [.inline-code-snipper]SUPERUSER[.inline-code-snipper] privileges/permissions to your Postgres database, unless you are using the ‘direct writes’ mode.
PowerSync does not modify your Postgres:
- Requires no modifications to your Postgres database except for enabling logical replication 3
- Requires read-only permissions to your database (only the [.inline-code-snipper]SELECT[.inline-code-snipper] and replication privileges)
ElectricSQL’s tight coupling to Postgres vs. PowerSync’s loose coupling
Developers should also consider that ElectricSQL’s architecture makes it tightly-coupled to your Postgres schema and configuration:
- ElectricSQL places restrictions on what you can have in your Postgres schema. For example, Check and Unique constraints are not supported by ElectricSQL and need to be removed from a table’s schema before “electrifying” that table.
- Data transformations between Postgres and SQLite are not possible with ElectricSQL — the client-side schema will match the server-side schema (although it is possible to do basic filtering of columns).
- Only specific Postgres types are supported. If you are using custom types in your Postgres database (e.g. for PostGIS), you would need to look into whether this can be supported (refer to “Local migrations” in the ElectricSQL docs).
- The database configuration is exclusively used for defining validation and access controls e.g. using Check constraints and DDLX (as mentioned above)
- ElectricSQL performs automatic client-side migrations to keep the client-side schema in sync with the server-side Postgres schema. This may cause complications if your schema changes and users are still running older client versions.
- All Postgres migrations need to run through the ElectricSQL migrations proxy (which allows ElectricSQL to enforce its restrictions and make its required modifications to the Postgres schema/configuration). If you make changes to your Postgres schema without using the ElectricSQL proxy, ElectricSQL will malfunction 4. This means that your migrations tooling must be configured to always use this ElectricSQL proxy. If you use a backend framework, you need to set it up to run its migrations (but not all database traffic) through the proxy.
PowerSync: Loose coupling to Postgres
By contrast, PowerSync is loosely coupled to Postgres, creating a layer of flexibility between your Postgres schema and configuration and the client-side SQLite schema.
- When defining Sync Rules, you can write custom SQL queries that can (optionally) perform transformations on the Postgres data/schema.
- You have control over defining the client-side schema. You can automatically generate a default schema based off of your Postgres schema, and/or you can customize it based on your needs. The Postgres and SQLite schemas can be relatively independent of each other. In fact, PowerSync does not actually enforce a hard schema on the SQLite database: PowerSync syncs “schemaless” data, and then applies your client-side schema on top of that using SQLite views.
ElectricSQL vs. PowerSync functionality and limitations
Something else to take into consideration is that ElectricSQL is currently in “open alpha”. The team has said that they do not currently recommend production use, and there are features missing that may be needed for production deployment.
Here’s a quick rundown of some differences in features and limitations, accurate as of the time of publishing this blog post:
| ElectricSQL functionality | PowerSync functionality |
|---|---|
| Dynamic partial replication is experimental (controlling what data syncs to which users). Shapes are available in experimental form, and DDLX-defined permissions have not yet been integrated with Shapes. | Dynamic partial replication is available and production-ready. See PowerSync Sync Rules. |
| Permissions / access control not yet available. The system cannot currently place restrictions on user writes applied to the Postgres database. | Permissions / access control available: • Read path: Sync Rules provide server-side control of which data syncs to which users. • Write path: Writes are sent through your existing backend application, allowing you to apply your own permissions / access control. |
| Built-in ORM. ElectricSQL comes with a strong built-in Prisma-inspired ORM for the client-side SQLite database, and also allows raw SQL access. | Limited ORM integrations. PowerSync currently provides a limited set of ORM integrations for the client-side SQLite database — see here for details. |
| Open-source, self-hosted: ElectricSQL is an open-source project and the sync service needs to be self-hosted. | Open-source & source-available, managed/hosted or self-hosted: PowerSync is currently offered as both a managed/hosted cloud service and self-hosted. Client SDKs are open-source (Apache 2.0 license) and a source-available version of the PowerSync Service is available as of May 31, 2024 (PowerSync Open Edition). |
| Conflict resolution cannot be customized. Pre-defined CRDTs are used for conflict resolution, which may result in conflict resolution policies that do not necessarily suit a developer's needs for a particular system. Some configuration of CRDTs will be supported in the future (see here) but note that this by itself does not mean deeper customization will be possible. | Custom conflict resolution strategies can be implemented since the developer is in control of the write process to the database. The developer can apply custom logic to conflict detection and resolution, including using CRDTs as data types (stored in Postgres as blob data) for e.g. text/documents. |
| Only JavaScript-based environments are officially supported. ElectricSQL currently only officially supports JavaScript-based client-side environments. This means that official support for native environments such as Kotlin, Swift and Flutter is not available. There was an unofficial community port for Dart/Flutter which was deprecated when 'electric-next' was announced. | Cross-platform environments supported. PowerSync currently has support for a mix of native and JavaScript-based environments, including Flutter, React Native and a plain JavaScript SDK for web browsers, with a Kotlin SDK in public alpha and Swift (iOS) in private alpha. |
| Additive migrations only. ElectricSQL only supports additive migrations on the database schema. | Various migration scenarios are supported , as documented here. |
| Postgres 'public' schema only. Only tables in the 'public' schema in Postgres can be accessed/synced by ElectricSQL. | Any Postgres schema. Any schema in your Postgres database can be accessed/synced by PowerSync. |
| Web browsers: Separate database per tab. ElectricSQL currently provides a separate SQLite database per browser tab when used on the web. | Web browsers: Multiple tabs concurrency. Where supported, PowerSync allows the same SQLite database to be accessed and updated across multiple tabs in the user's web browser. |
Footnotes
-
Support for additional databases is planned for PowerSync, including MySQL and Microsoft SQL Server / Azure SQL. ↩
-
Note: PowerSync is different from systems like WatermelonDB where you have to build your backend functionality for the read path , which can put a heavier burden on the developer in terms of scope and complexity. PowerSync provides the PowerSync Service which handles the read path of syncing to users, including the complexities of dynamic partial replication. PowerSync only relies on your backend for handling writes. On the client-side, PowerSync handles the complexity of queueing writes so that they can be retried if connectivity / the backend is not immediately available. ↩
-
In some cases denormalization is required to effectively partition the data to sync to different users. ↩
-
There are workarounds to do migrations without the proxy, but it requires more effort. ↩